

1 安装dataspell与anaconda
1安装dataspell与anaconda
这一步可以自己搞定。
但是你得把anaconda的环境变量添加进你的用户的path里面。
前面那里改成你的anaconda安装的位置就行。
Q:anaconda是什么鬼
A:是一个打包了很多深度学习库的环境管理软件(确信
1.2基本的anaconda操作
创建一个叫做py37,的python3.7版本的环境
conda create --name py37 python=3.7启动这个环境
activate py37关闭这个环境
deactivate py37显示已经安装好的环境
conda info --envs复制环境(不用加上尖括号哈)
conda create --name <new_env_name> --clone <copied_env_name>删除环境
conda remove --name <env_name> --all查看已经安装的包
conda list查找想要安装的包
conda search <text>在当前环境下安装包
conda install <package_name>2 张量
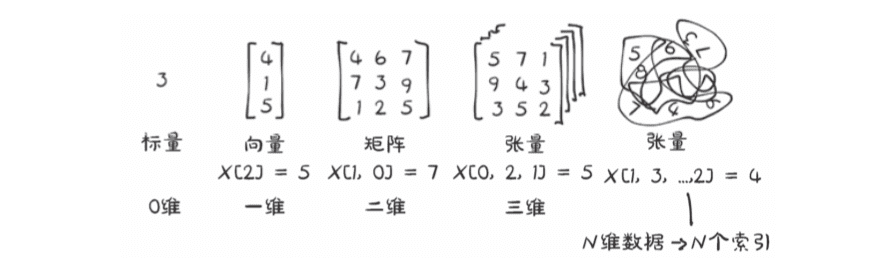
2.1 什么是张量
这里的张量和其他意义的张量没啥关系,只是一个多维的数据
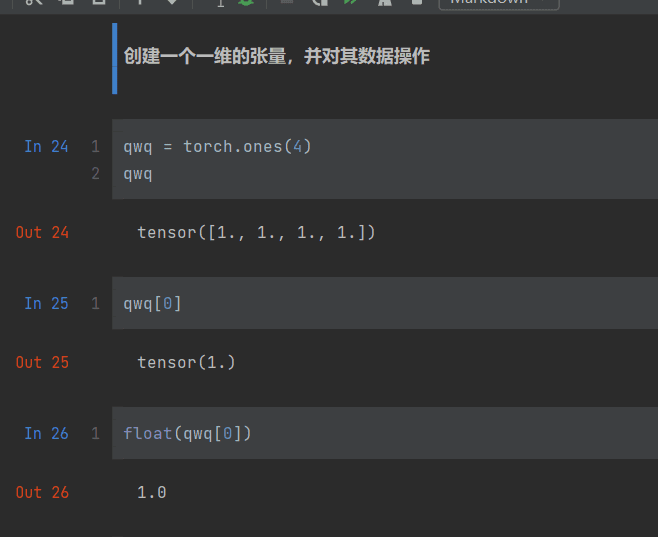
2.2 张量的一些操作
这个代码编辑的插件一坨屎,我就直接截图了
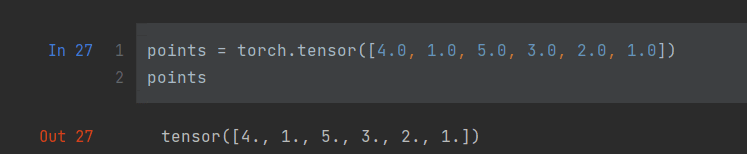
同样的,把列表传递给张量也是可行的
试图用zeros函数函数构造多维数组(2维,一共三组数)
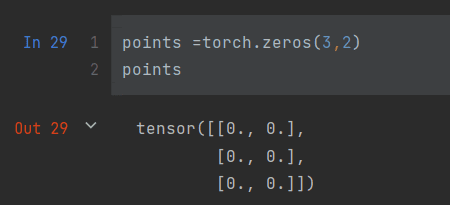
此时我们访问的数据不再是一个数字,而是一个二维的数组
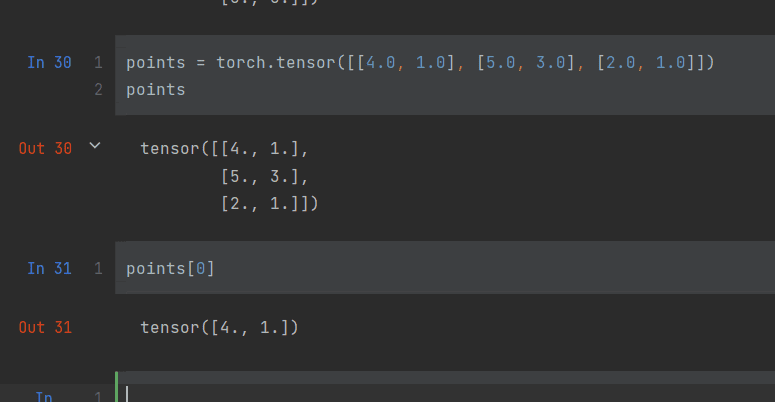
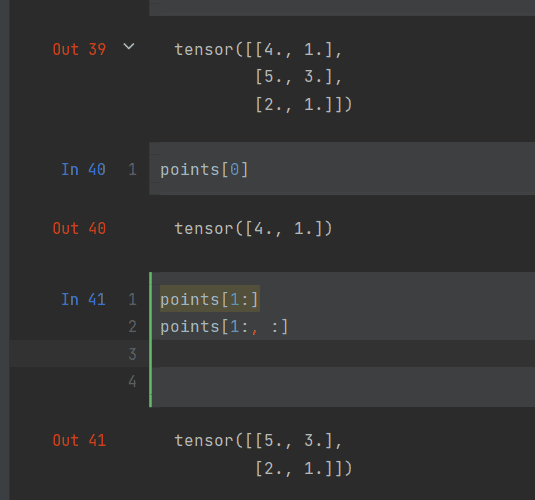
索引张量,类似列表的操作方法(你说是那就是
2.3 张量的元素类型
torch.float32 或 torch.float:32 位浮点数。
torch.float64 或 torch.double:64 位双精度浮点数。
torch.float16 或 torch.half:16 位半精度浮点数。
torch.int8:8 位有符号整数。
torch.uint8:8 位无符号整数。
torch.int16 或 torch.short:16 位有符号整数。
torch.int32 或 torch.int:32 位有符号整数。
torch.int64 或 torch.long:64 位有符号整数。
torch.bool:布尔型。
对于上面的张量创建方式,我们可以在指定其类型

当然,你可以用 dtype方法来看张量的类型

对于类型的转换,自动的to方法倒是不错的选择

2.4 张量的使用
这里似乎有一大堆函数,还是看看手册吧(我有空再来翻译翻译,妈耶太哈人了
在这里:torch.Tensor — PyTorch 1.13 documentation
有空翻译翻译再搬运搬运,太多了
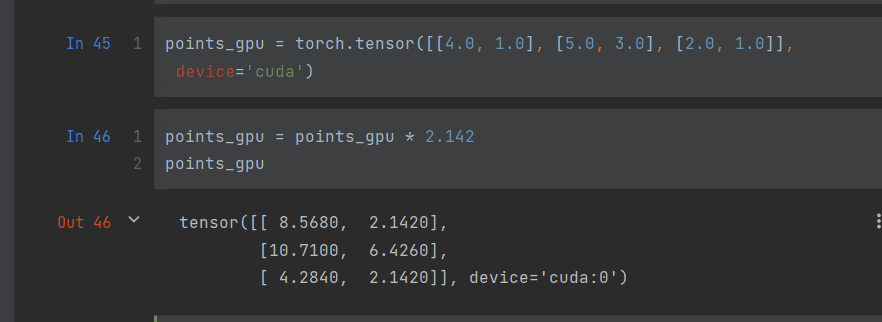
2.5 So NVIDIA, FUCK U(cuda的使用)
在gpu上进行张量运算:只需要在初始化张量的时候设置好就行
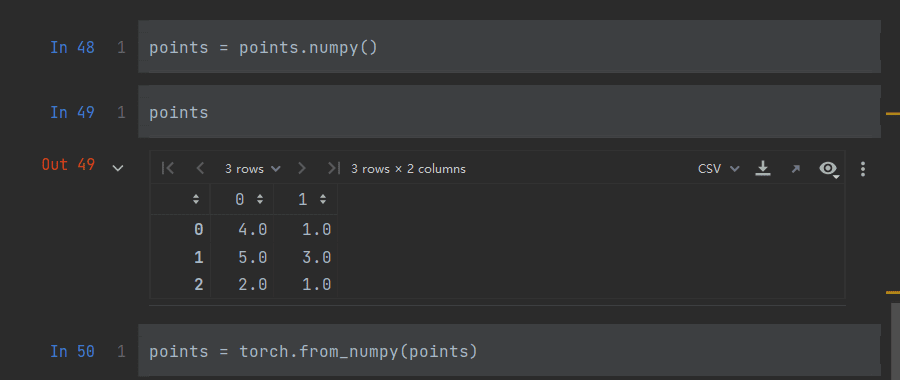
2.6 与numpy数组的转换
使用numpy()方法
使用from_numpy(<name>)方法
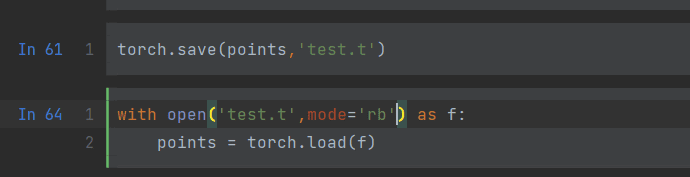
2.7 储存张量与读取张量,序列化张量
使用save(<name>,<location>);load(<location>)方法来实现,loaction可以用python的with open(<location>) as f: 来实现不那么长
3 处理真实的数据
3.1 图像的处理
纵使我很喜欢用hsv来搞opencv的图像识别,但是对于深度学习还是用RGB吧,直观一些(大嘘)
读取图像(我超不用opencv)
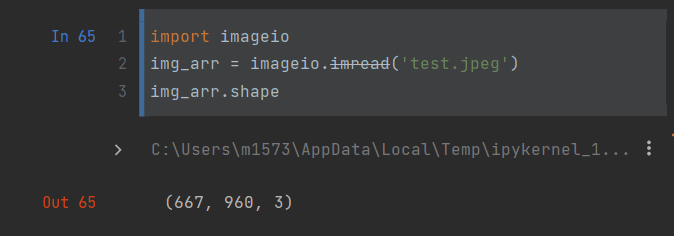
我们看到一个三通道的 677*960 的张量,嗯
当然你也可以用opencv读取
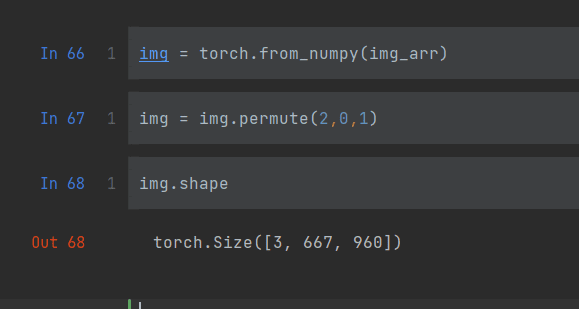
对于一张图片,常见的三维数组分别是“高 宽 通道”,出于效率的考虑,我们切换为“通道 高 宽”,使用permute()方法来实现。
permute的参数其实很搞笑,就是自己重新用数字排列一下你想要的顺序(记得列表的第一个索引是0哦)
然后可以再次使用zeros()方法来构造一个张量存储多组图像数据,就像这样(例子中是三个)
最后对图像进行一点小小的映射(为了后面的神经网络的计算服务

3.2 试图预测葡萄酒的味道
我们先下载一份来自什么葡萄酒的cvs文件
然后用cvs库来读取这个玩意
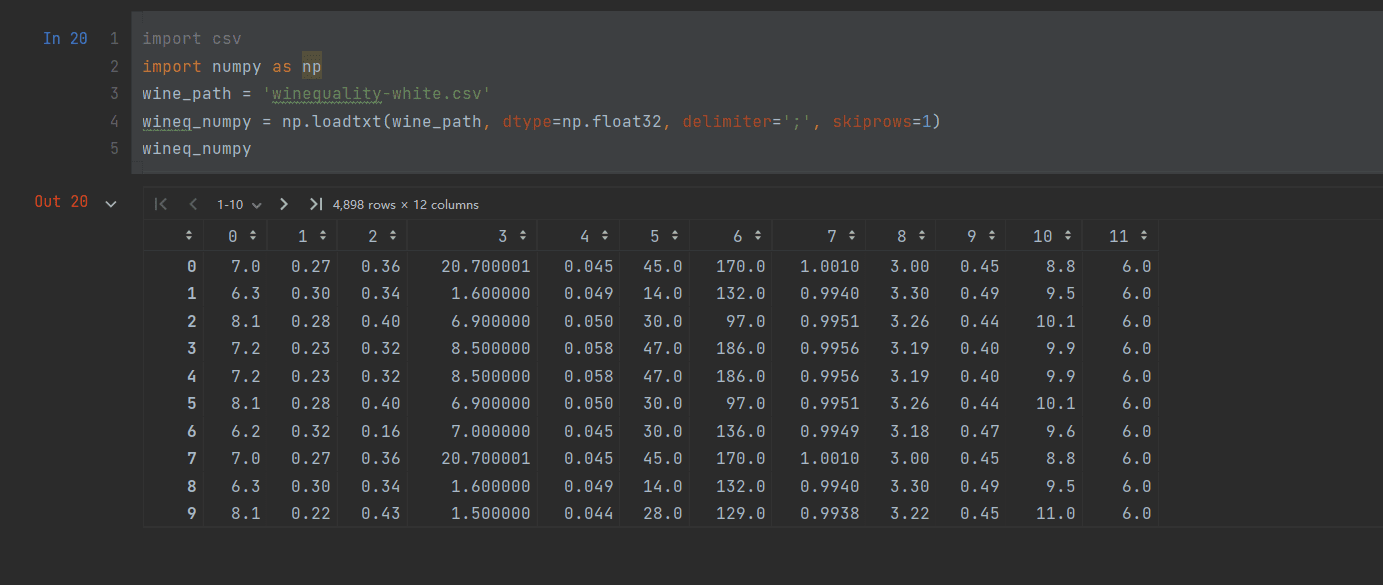
loadtxt()的一堆参数里面 我们规定了数据路径,数据类型,数据分隔符以及需要从第几排开始读取
再通过上面的方法转换为一个张量
