
前言
为了给例会群里搞点乐子,于是决定搞一个东方角色的识别,首先想到的其实就是ConvNext网络,对于这个一百来个角色的分类任务,它足以胜任。
qwqpap/touhou_guess · Hugging Face
ConvNext网络介绍
(99+ 封私信 / 90 条消息) ConvNeXt—— 一个能挑战 Vision Transformer 的卷积神经网络(万字长文,从原理到代码演示) – 知乎
懒得介绍了,看看知乎得了
数据来源
预期的角色数量大概在120多人,有一些旧作的角色可能被狠狠抛弃了。
事后发现纯狐和三花也被忘掉了)
每个角色大概100多个图片,最开始的数据集来自于Preacher-26/touhou-embeddings-dataset · Datasets at Hugging Face
特别感谢Preacher老师的分享。
之后再次获得了Renko_1055的神秘python脚本,使我的数据集数量获得了极大的提高。
稍微修改一下
对于原版的ConvNext,我们需要给最后一层网络直接改成全链接到所有的角色上面输出一百多个预测值。
import os
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
from PIL import Image
import timm
from sklearn.metrics import f1_score, precision_score, recall_score
import matplotlib.pyplot as plt
import json
from tqdm import tqdm
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
# 读取角色列表
with open('characters.json', 'r', encoding='utf-8') as f:
characters_data = json.load(f)
characters = characters_data['characters']
num_classes = len(characters)
print(f'Total characters: {num_classes}')
# 定义标签映射
label_to_idx = {char: idx for idx, char in enumerate(characters)}
# 数据预处理
transform = transforms.Compose([
transforms.Resize((384, 384)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# CutMix 数据增强实现
import numpy as np
def cutmix(data, targets, alpha=0.5, cutmix_prob=0.5):
"""
CutMix 数据增强,适用于多标签分类
参数:
data: 输入图像 batch,shape [B, C, H, W]
targets: 输入标签 batch,shape [B, num_classes]
alpha: 控制贴入图像的大小比例 (0.1表示10%,0.2表示20%)
cutmix_prob: 应用 CutMix 的概率
返回:
mixed_data: CutMix 处理后的图像
mixed_targets: CutMix 处理后的标签
"""
batch_size = data.size(0)
indices = torch.randperm(batch_size)
shuffled_data = data[indices]
shuffled_targets = targets[indices]
# 生成随机概率
if np.random.random() < cutmix_prob:
# 获取图像尺寸
B, C, H, W = data.shape
# 计算贴入图像的大小:基于alpha的固定比例,确保有内容
paste_size_ratio = alpha # 例如alpha=0.2表示贴入20%大小的图像
paste_h = int(H * paste_size_ratio)
paste_w = int(W * paste_size_ratio)
# 确保paste大小至少为1x1
paste_h = max(1, paste_h)
paste_w = max(1, paste_w)
# 将shuffled_data resize到paste大小
import torch.nn.functional as F
resized_shuffled = F.interpolate(shuffled_data, size=(paste_h, paste_w), mode='bilinear', align_corners=False)
# 随机选择贴入位置
paste_x = np.random.randint(0, W - paste_w + 1)
paste_y = np.random.randint(0, H - paste_h + 1)
# 应用 CutMix:将resize后的图像贴到原图上
data[:, :, paste_y:paste_y+paste_h, paste_x:paste_x+paste_w] = resized_shuffled[:, :, :, :]
# 多标签分类:标签取并集
targets = torch.max(targets, shuffled_targets)
return data, targets
# 自定义数据集类
class TouhouDataset(Dataset):
def __init__(self, csv_file, root_dir, transform=None, split=None):
self.df = pd.read_csv(csv_file)
# 根据split筛选数据
if split is not None:
self.df = self.df[self.df['split'] == split]
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
img_path = os.path.join(self.root_dir, self.df.iloc[idx]['file_name'])
# 处理PNG图像的超大iCCP块问题
from PIL import PngImagePlugin
original_max = PngImagePlugin.MAX_TEXT_CHUNK
PngImagePlugin.MAX_TEXT_CHUNK = 100 * 1024 * 1024 # 100MB
try:
image = Image.open(img_path).convert('RGB')
finally:
# 恢复原始限制
PngImagePlugin.MAX_TEXT_CHUNK = original_max
# 处理标签
tags = self.df.iloc[idx]['tags'].split(';')
label = torch.zeros(num_classes, dtype=torch.float32)
for tag in tags:
if tag in label_to_idx:
label[label_to_idx[tag]] = 1.0
if self.transform:
image = self.transform(image)
return image, label
# 定义模型
class TouhouClassifier(nn.Module):
def __init__(self, num_classes):
super().__init__()
# 加载预训练的ConvNeXt-B
self.model = timm.create_model('convnext_base', pretrained=True)
# 修改头部以适应多标签分类
n_features = self.model.head.fc.in_features
self.model.head.fc = nn.Linear(n_features, num_classes)
def forward(self, x):
# 输出logits,后续使用BCEWithLogitsLoss
return self.model(x)
if __name__ == '__main__':
# 加载数据集
dataset_path = './Fast-Danbooru-Dataset-DL/touhou-embeddings-dataset'
csv_file = os.path.join(dataset_path, 'labels.csv')
root_dir = os.path.join(dataset_path, 'images')
# 使用CSV文件中的split字段划分训练集和验证集
train_dataset = TouhouDataset(csv_file=csv_file, root_dir=root_dir, transform=transform, split='train')
val_dataset = TouhouDataset(csv_file=csv_file, root_dir=root_dir, transform=transform, split='val')
print(f'Dataset loaded successfully!')
print(f'Train set size: {len(train_dataset)}')
print(f'Validation set size: {len(val_dataset)}')
print(f'Train:Val ratio: {len(train_dataset)/(len(train_dataset)+len(val_dataset)):.2%}:{len(val_dataset)/(len(train_dataset)+len(val_dataset)):.2%}')
# 创建数据加载器,减小batch size到8
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False, num_workers=4)
model = TouhouClassifier(num_classes=num_classes).to(device)
# 定义损失函数和优化器
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-5)
# 开启混合精度训练 (AMP)
scaler = torch.amp.GradScaler('cuda')
# 训练参数
total_epochs = 200
best_val_loss = float('inf')
train_losses = []
val_losses = []
val_f1_scores = []
# CutMix 参数设置
cutmix_alpha = 0.2 # 关键参数:控制裁剪块大小,小值表示小块裁剪
cutmix_prob = 0.5 # CutMix 应用概率,50%的概率应用
# 检查是否存在已训练的模型,支持从最新epoch继续训练
output_dir = './output'
start_epoch = 1
# 检查是否存在训练状态文件
state_file = os.path.join(output_dir, 'training_state.pth')
if os.path.exists(state_file):
# 加载训练状态
state = torch.load(state_file, map_location=device)
# 加载模型权重
model.load_state_dict(state['model_state_dict'])
# 加载优化器状态
optimizer.load_state_dict(state['optimizer_state_dict'])
# 加载scaler状态
scaler.load_state_dict(state['scaler_state_dict'])
# 加载最佳损失值
best_val_loss = state['best_val_loss']
# 加载训练历史
train_losses = state['train_losses']
val_losses = state['val_losses']
val_f1_scores = state['val_f1_scores']
# 设置起始epoch
start_epoch = state['epoch'] + 1
print(f'Loaded training state from {state_file}')
print(f'Best validation loss so far: {best_val_loss:.4f}')
print(f'Will continue training from epoch {start_epoch}')
else:
# 检查是否存在单独的epoch模型文件
epoch_files = [f for f in os.listdir(output_dir) if f.startswith('model_epoch_') and f.endswith('.pth')]
if epoch_files:
# 提取epoch号并找到最大值
latest_epoch = max([int(f.split('_')[2].split('.')[0]) for f in epoch_files])
# 加载最新模型
latest_model_path = os.path.join(output_dir, f'model_epoch_{latest_epoch}.pth')
model.load_state_dict(torch.load(latest_model_path, map_location=device))
print(f'Loaded latest model from {latest_model_path}, epoch {latest_epoch}')
# 设置起始epoch
start_epoch = latest_epoch + 1
print(f'Will continue training from epoch {start_epoch}')
# 训练循环
for epoch in range(start_epoch - 1, total_epochs): # 从start_epoch-1到total_epochs-1
print(f'\n=== Epoch {epoch+1}/{total_epochs} ===')
# 训练阶段
model.train()
train_loss = 0.0
print('Training...')
train_progress = tqdm(train_loader, desc='Train', leave=True)
# 梯度累积参数
accum_steps = 2 # 等效batch size = 8 * 2 = 16
optimizer.zero_grad()
for i, (images, labels) in enumerate(train_progress):
images = images.to(device)
labels = labels.to(device)
# 应用 CutMix 数据增强
# images, labels = cutmix(images, labels, alpha=cutmix_alpha, cutmix_prob=cutmix_prob)
# 使用 autocast 开启混合精度训练
with torch.amp.autocast('cuda'):
outputs = model(images)
loss = criterion(outputs, labels) / accum_steps # 除以累积步数
# 混合精度反向传播
scaler.scale(loss).backward()
# 累加损失
batch_loss = loss.item() * accum_steps * images.size(0) # 恢复原始loss值
train_loss += batch_loss
# 更新进度条
train_progress.set_postfix({'Batch Loss': f'{loss.item() * accum_steps:.4f}'}) # 显示原始loss
# 梯度累积:每accum_steps步更新一次参数
if (i + 1) % accum_steps == 0:
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
train_loss /= len(train_loader.dataset)
train_losses.append(train_loss)
print(f'Train Loss: {train_loss:.4f}')
# 验证阶段
model.eval()
val_loss = 0.0
all_preds = []
all_labels = []
print('Validating...')
val_progress = tqdm(val_loader, desc='Val', leave=True)
with torch.no_grad():
for images, labels in val_progress:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
# 累加损失
batch_loss = loss.item() * images.size(0)
val_loss += batch_loss
# 更新进度条
val_progress.set_postfix({'Batch Loss': f'{loss.item():.4f}'})
# 转换为二进制预测(阈值0.5)
preds = torch.sigmoid(outputs) > 0.5
all_preds.extend(preds.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
val_loss /= len(val_loader.dataset)
val_losses.append(val_loss)
print(f'Val Loss: {val_loss:.4f}')
# 计算指标
all_preds = np.array(all_preds)
all_labels = np.array(all_labels)
f1 = f1_score(all_labels, all_preds, average='micro')
precision = precision_score(all_labels, all_preds, average='micro')
recall = recall_score(all_labels, all_preds, average='micro')
val_f1_scores.append(f1)
print(f'Val F1 Score: {f1:.4f}')
print(f'Val Precision: {precision:.4f}')
print(f'Val Recall: {recall:.4f}')
print('-' * 50)
# 每2个epoch保存一次模型
if (epoch + 1) % 2 == 0:
epoch_model_path = f'./output/model_epoch_{epoch+1}.pth'
torch.save(model.state_dict(), epoch_model_path)
print(f'Saved model for epoch {epoch+1} to {epoch_model_path}')
# 保存最佳模型
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model_path = './output/best_model.pth'
torch.save(model.state_dict(), best_model_path)
print(f'Saved best model with val loss: {best_val_loss:.4f} to {best_model_path}')
# 保存训练状态(用于继续训练)
state = {
'epoch': epoch+1,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scaler_state_dict': scaler.state_dict(),
'best_val_loss': best_val_loss,
'train_losses': train_losses,
'val_losses': val_losses,
'val_f1_scores': val_f1_scores
}
state_file_path = './output/training_state.pth'
torch.save(state, state_file_path)
print(f'Saved training state to {state_file_path}')
# 绘制训练曲线
plt.figure(figsize=(15, 10))
# 损失曲线
plt.subplot(2, 2, 1)
plt.plot(range(1, len(train_losses)+1), train_losses, label='Train Loss')
plt.plot(range(1, len(val_losses)+1), val_losses, label='Val Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
# F1分数曲线
plt.subplot(2, 2, 2)
plt.plot(range(1, len(val_f1_scores)+1), val_f1_scores, label='Val F1 Score')
plt.xlabel('Epochs')
plt.ylabel('F1 Score')
plt.title('Validation F1 Score')
plt.legend()
# 额外绘制精度和召回曲线(如果有的话)
if 'val_precisions' in locals() and 'val_recalls' in locals():
plt.subplot(2, 2, 3)
plt.plot(range(1, len(val_precisions)+1), val_precisions, label='Val Precision')
plt.plot(range(1, len(val_recalls)+1), val_recalls, label='Val Recall')
plt.xlabel('Epochs')
plt.ylabel('Score')
plt.title('Validation Precision and Recall')
plt.legend()
plt.tight_layout()
plt.savefig('./output/training_curves.png')
plt.close()
# 打印训练结果摘要
print('\nTraining Results Summary:')
print(f'Total epochs trained: {len(train_losses)}')
print(f'Best validation loss: {min(val_losses):.4f} at epoch {val_losses.index(min(val_losses))+1}')
print(f'Best validation F1 score: {max(val_f1_scores):.4f} at epoch {val_f1_scores.index(max(val_f1_scores))+1}')
print(f'Training curves saved to ./output/training_curves.png')
print('Training completed!')当然这个数据集用的是上面huggingface里面的数据集。
你也可以通过:ConvNeXT – Hugging Face 文档 来自己搞一个用。
数据清洗
对于这个任务,上文中的ConvNeXt-B 384×384已经完全彻底的能满足需求,需要注意的就是从网上爬下来的各种脏数据问题,首先是重复图片/相似图片。
思路非常简单,计算图片哈希,然后计算两个哈希值的汉明距离,用这个作为阈值来直接删除过于相似的图片。
当然这个过程因为哈希碰撞难免误伤,我的解决办法是分角色来应用,就会少很多碰撞的情况。
另一方面的各种黑白的漫画,这个在爬取Safebooru上面图片的时候能够直接获取其标签,那么就可以完美地直接删除各种漫画了。
在做完这一切后就可以开始训练了。
神秘的训练
我们最开始使用的ConvNeXt-B 224×224网络训练到loss极低后再改为了ConvNeXt-B 384×384,还好这个网络并不在意输入层的分辨率,所以允许偷这个懒。
数据增强
在训练过程中考虑使用了CutMix,但是效果不佳,F1 score也大降,故放弃。
另一方面考虑可能用随机化的饱和度与色相可能会有助于训练,但是现在这个情况我感觉够了。
在batch size 16时,总数据集1.6w张,40epoch后验证损失来到了0.01上下,被我人为早停了(划掉)
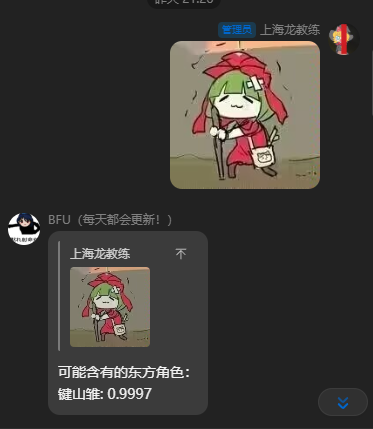
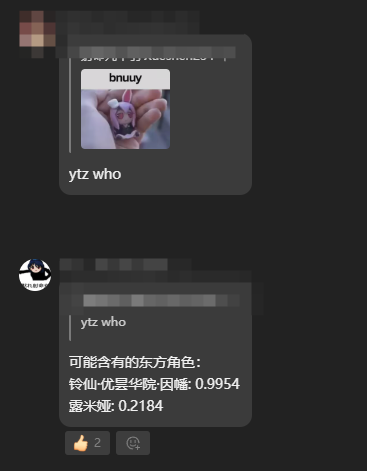
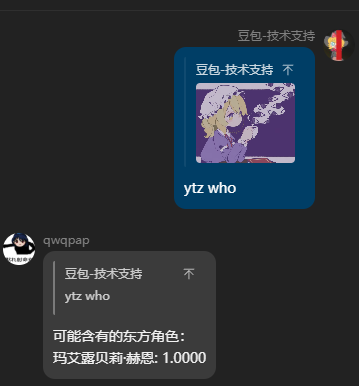
展示一下
这个模型被我接入了qqbot在例会群里耍

模型文件比较巨大,考虑例会结束后开源一下。